Domain specificity follows from interactions between overlapping maps March 10, 2008
Posted by Johan in Face Perception, Neuroscience, Sensation and Perception, Theory.1 comment so far

![]() I can’t simplify the title beyond that, but don’t run away yet, the idea itself is straight forward once the terminology is explained. Skip ahead two paragraphs if you know what domain specificity means.
I can’t simplify the title beyond that, but don’t run away yet, the idea itself is straight forward once the terminology is explained. Skip ahead two paragraphs if you know what domain specificity means.
Recognition of objects in the visual scene is thought to arise in inferior temporal and occipital cortex, along the ventral stream (see also this planned Scholarpedia article on the topic by Ungerleider and Pessoa – might be worth waiting for). That general notion is pretty much where consensus ends, with the issue of how different object categories are represented remaining controversial. Currently, the dominant paradigm is that of Nancy Kanwisher and colleagues, who hold that a number of domain-specific (that is, modular) areas exist, which each deal with the recognition of one particular object category. The most widely accepted among these are the fusiform face area (FFA), the parahippocampal place area (PPA), the occipital face area (OFA), the extrastriate body area (EBA), and the lateral occipital complex (LO), which is a bit of a catch-all region for the recognition of any object category that doesn’t fall into one of the domains with their own area. Usually, the face-selective part of the superior temporal sulcus (STS) is also included.
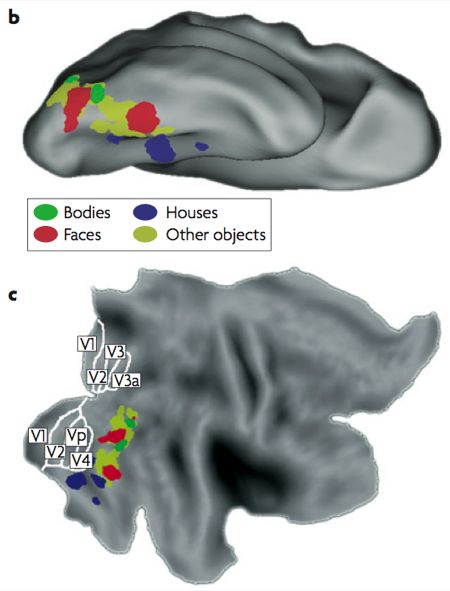
Typical locations of object areas by category. B is an upside down down, C is flattened
This modular view of the visual recognition has received a lot of criticism. However, the undeniable success of the functional localiser approach to fMRI analysis, in which responses are averaged across all voxels in each of the previously-mentioned areas, has led to widespread acceptance of the approach. Essentially, then, the domain specific account seems to be accepted because recording from a functionally-defined FFA, for instance, seems to yield results that make a lot of sense for face perception.
When you think about it, the domain specific account in itself is a pretty lousy theory of object recognition. It does map object categories onto cortex, but it is considerably more difficult to explain how such a specific representation might be built on input from earlier, non-object specific visual areas. This brings us to today’s paper, which proposes a possible solution (op de Beeck et al, 2008). The bulk of the paper is a review of previous research in this area, so give it a read for that reason if you want to get up to speed. The focus of this post is on the theoretical proposal that op de Beeck et al (2008) make towards the end of the paper, which goes something like this:
Ventral stream areas contain a number of overlapped and aligned topographical maps, where each maps encodes one functional property of the stimulus. Op de Beeck et al (2008) suggest that properties might include shape, functional connectivity, process, and eccentricity. Let’s go through each of those suggestions in turn (the following is based on my own ideas – op de Beeck et al don’t really specify how the topography of these featural maps might work):
A shape map might encode continuous variations of for instance angularity and orientation of parts of the stimulus. So one imaginary neuron in this map might be tuned to a sharp corner presented at an upright orientation (see Pasupathy & Connor, 2002 for an example of such tuning in V4), and topographically, the map might be laid out with angularity and curvature as the x and y dimensions in the simplest case.
Functional connectivity is hard to explain – read the article I just linked if you’re curious, but let’s just call it brain connectivity here. A map of brain connectivity is a topographical layout of connections to other areas – for instance, one part of the map might be more connected to earlier visual areas (such as V4), while another part of the map might connect more with higher-order areas that deal with memory or emotion (e.g., hippocampus, amygdala).
The process map is a tip of the hat to some of Kanwisher’s strongest critics, such as Tarr & Gauthier (2000), who argued that the ventral stream isn’t divided by object category, but by the visual processing that is used. So for example, the FFA is actually an area specialised for expert within-category discrimination of objects (faces or otherwise), which happens to appear face-specific because we have more experience with faces than with other categories. Some parts of the map might deal with such expertise discriminations, while others might deal with more general between-category classification.
Eccentricity is a fancy term for distance from the fixation point (ie, the fovea) in retinal coordinates. If you hold your finger slightly left of your fixation point and continue to move it left, you are increasing the eccentricity of the stimulus. Eccentricity and its complicated partner polarity (visual angle) reflect the two basic large-scale topographical principles in early visual areas, but such maps can be found throughout the visual system.
Incidentally, the eccentricity map is the only of these proposed maps for which there is currently good evidence in this part of the brain (Levy et al, 2001). The part that corresponds to the FFA has a foveal (or central) representation of the visual field, which makes sense considering that we tend to look directly at faces. Conversely, the PPA has a peripheral representation, as might be expected since most of us don’t spend much time fixating on the scenery.
The central proposal is that in an area such as the FFA, the face-specific response is actually the combination of the concurrent, aligned activation of a number of different maps. For example, the FFA might correspond to responses tuned to rounded shapes in the shape map, to input from earlier visual areas in the functional connectivity map, to expert within-category discrimination in the process map, and to a foveal (central) representation in the eccentricity map.
To really get the kind of strong domain-specificity that is observed, these maps must display multiplicative interactions – op de Beeck et al (2008) suggest that if their simultaneous activations were just added to make up the fMRI response, you wouldn’t get the strong selectivity that is observed (so by implication, less strict modularists could do away with the multiplicative bit and get a map that corresponds better to their view of ventral areas).
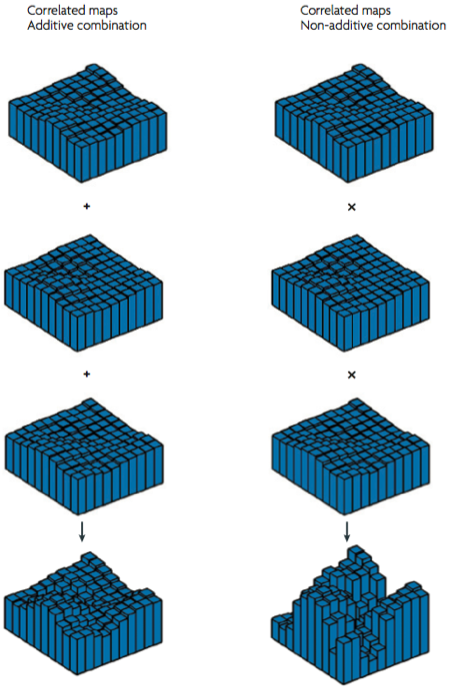
This is a pretty interesting idea, although wildly speculative. Note that with the exception of eccentricity, there really is very little evidence for this form of organisation. In other words, this theory is a theory not just in the scientific sense, but also in the creationist sense of the word. It definitely is an inspiring source of possible future experiments, however.
References
Levy, I., Hasson, U., Avidan, G., Hendler, T., & Malach, R. (2001). Center-periphery organization of human object areas. Nature Neuroscience, 4, 533-539. DOI: 10.1038/87490
Op de Beeck, H.P., Haushofer, J., Kanwisher, N.G. (2008). Interpreting fMRI data: maps, modules and dimensions. Nature Reviews Neuroscience, 9, 123-135. DOI: 10.1038/nrn2314
Pasupathy, A., & Connor, C.E. (2002) Population coding of shape in area V4. Nature Neuroscience, 5, 1332-1338. Link
Tarr, M.J., & Gauthier, I. (2000). FFA: a flexible fusiform area for subordinate-level visual processing automated by expertise. Nature Neuroscience, 3, 764-769. DOI: 10.1038/77666
Reducing the problem of face recognition to an average February 5, 2008
Posted by Johan in Applied, Cognition, Face Perception, Theory.2 comments

![]() Although computer software is now adept at face detection – Google’s image search does it, and so does you camera if you bought it within the past year – the problem of recognising a face as belonging to a specific individual has proved a hard nut to crack.
Although computer software is now adept at face detection – Google’s image search does it, and so does you camera if you bought it within the past year – the problem of recognising a face as belonging to a specific individual has proved a hard nut to crack.
Essentially, this is a problem of classification. A model for this process should be able to sort images of three persons into three separate categories. This is remarkably difficult to do. If you look at the sheer physical differences between images of the same person, they easily outnumber the differences between images of different persons, taken from the same angle under the same lighting conditions. In other words, the bulk of the physical variability between different face images is uninformative, as far as face recognition is concerned. Thus, this remains an area where humans effortlessly outperform any of the currently-available face recognition models.
Recent work by Mark Burton at the Glasgow Face Recognition Group suggests a solution by which computer models can achieve human-like performance at face recognition. By implication, such a model may also offer a plausible mechanism for how humans perform this task. The model that Burton et al (2005) proposed is best explained by this figure, which outlines the necessary processing steps:

For each face that the model is to learn, a number of example images are collected (as shown in A). These images are morphed to a standard shape (B), which makes it possible to carry out pixel-by-pixel averaging to create a composite (C). This composite is then used by the model to attempt to recognise a new set of images of the person.
This may sound relatively straight-forward, but the idea is novel. Most face recognition models that work with photographs use an exemplar-based algorithm, where the model stores each of the images it is shown. Such models do improve as more faces are added (since there are more exemplars that might possibly match), but not as much as an averaging model does as more pictures are added to the average (Burton et al, 2005). Furthermore, when noise is added in the form of greater variations in lighting, the exemplar model breaks down rapidly while the averaging model is largely unaffected.
Why is this model so effective? The averaging process appears to remove variability that is not relevant to personal identity (such as differences in lighting and shading, changes in hair style), while preserving information that is informative for recognition (eyebrows, eyes, nose, mouth, perhaps skin texture). The figure at the top of this post highlights this (from Burton et al, 2005). The pictures are shape-free averages, created from 20 exemplar pictures of each celebrity. To the extent that hair is present, it is usually blurry. But the pictures are eminently recognisable, even though you have in fact never seen any of these particular images before (since they are composites). Indeed, Burton et al (2005) showed that participants were faster to recognise these averages than they were at recognising the individual exemplar pictures.
In the latest issue of Science, Jenkins and Burton (2008) presented an unusual demonstration of the capabilities of this model. They pitted their model against one of the dominant commercial face-recognition systems (FaceVACS). The commercial model has been implemented at MyHeritage, a website that matches pictures you submit to a database of celebrities.
Jenkins and Burton (2008) took advantage of this by feeding the website a number of images from the Burton lab’s own celebrity face database. Note that the website is all about matching your face to a celebrity, so if an image of Bill Clinton from the Burton database is given as input, you would expect the face recognition algorithm to find a strong resemblance to the Bill Clinton images stored by MyHeritage. Overall, performance was unimpressive – 20 different images of 25 male celebrities were used, and the commercial face algorithm matched only 54% of these images to the correct person. This highlights how computationally difficult face recognition is.
In order to see how averaging might affect the model’s performance, Jenkins and Burton (2008) took the same 20 images and created a shape-free average for each celebrity. Each average was then fed into the model.
This raised the hit rate from 54% to 100%.
The model that Burton is advocating is really one where individual face images are recognised with reference to a stored average. This finding is essentially the converse – the commercial model, which attempts to store information about each exemplar, is used to identify an average. But there is no reason why it wouldn’t work the other way around.
This demonstration suggests that as far as computer science is concerned, the problem of face recognition may be within our grasp. There are a few remaining kinks before we all have to pose for 20 passport pictures instead of one, however: the model only works if each exemplar is transformed, as shown in the figure above. As I understand it, this process cannot be automated at present.
While we’re on the computer science side I think it is also worth mentioning that there may be some ethical implications to automatic face recognition, especially in a country with one CCTV camera for every 5 inhabitants (according to Wikipedia). I have always dismissed the typical Big Brother concerns with the practical issue of how anyone would have time to actually watch the footage. If, however, automatic face recognition becomes common-place, you had better hope that your government remains (relatively) benevolent, because there will be no place to hide.
Turning to psychology, the assertion by Burton et al is that this model also represents to some extent what the human face recognition system is doing. This sounds good until you realise that face recognition is not hugely affected by changes in viewing position – you can recognise a face from straight on, in profile, or somewhere in between. This model can’t do that (hence the generation of a shape-free average), so if the human system works this way, it must either transform a profile image to a portrait image in order to compare it to a single, portrait average, or it must store a number of averages for different orientations, which leads to some bizarre predictions (for example, you should have an easier time recognising the guy who sits next to you in lecture from a profile image, because that’s how you have usually viewed him).
That being said, this model offers an extremely elegant account of how face recognition might occur – read the technical description of FaceVACS to get a taste for how intensely complex most conventional face recognition models are (and by implication, how complex the human face recognition system is thought to be). The Burton model has a few things left to explain, but it is eminently parsimonious compared to previous efforts.
References
Burton, A.M., Jenkins, R., Hancock, P.J.B., & White, D. (2005). Robust representations for face recognition: The power of averages. Cognitive Psychology, 51, 256-284.
Jenkins, R., Burton, A.M. (2008). 100% Accuracy in Automatic Face Recognition. Science, 319, 435. DOI: 10.1126/science.1149656
